
Years in Business

How AI Can Help Your Business Grow
Read Full Article
























Nextwebi offers specialized RAG development services designed to build data-grounded Generative AI systems using enterprise knowledge sources. Our services focus on designing robust retrieval architectures, optimizing relevance, and integrating structured and unstructured data into scalable RAG pipelines. Each capability is engineered to support accuracy, performance, and controlled AI behavior in production environments.
We analyze existing data ecosystems and business workflows to design RAG architectures optimized for retrieval accuracy, response latency, and system scalability. This includes defining chunking strategies, retrieval layers, and model interaction patterns.
Our team structures and processes enterprise data using domain-aware chunking, hybrid embedding techniques, and semantic indexing. This improves contextual recall and increases retrieval relevance across large and evolving datasets.
We integrate RAG pipelines with SQL and NoSQL databases, enabling AI systems to query CRM, ERP, analytics, and transactional systems alongside unstructured documents for richer, context-aware responses.
Nextwebi develops query-aware retrieval logic using ranking, filtering, and relevance scoring techniques. These mechanisms prioritize the most contextually accurate data for each request, reducing noise in generated outputs.
We build multimodal RAG systems capable of retrieving insights from PDFs, scanned documents, images, and spreadsheets using unified embeddings. This enables knowledge extraction without manual preprocessing.
Our RAG fine-tuning services focus on prompt routing, response structuring, and alignment with domain-specific language patterns. This improves output consistency and contextual accuracy without retraining base models.
We optimize retrieval performance through query expansion, vector tuning, and A/B testing strategies. These techniques improve precision and reduce irrelevant context injection in AI responses.
We implement validation and freshness checks to manage outdated, redundant, or restricted data sources. This ensures RAG systems operate within compliance boundaries, especially in regulated industries.
Nextwebi delivers specialized RAG development services that combine large language models with intelligent retrieval layers to generate responses grounded in enterprise data. Our approach majorly focuses on structuring unstructured content, generating high-quality embeddings, and implementing semantic search mechanisms that helps to surface the most relevant context for each query. This architecture supports AI systems to produce precise, context-rich outputs aligned and in sync with business knowledge.
Our RAG implementations are designed for production environments, with careful attention to vector database selection, retrieval tuning, and latency optimization. Our team also has expertise in integrating access controls, data isolation, and query filtering to support secure usage across internal teams and customer-facing applications. The retrieval pipeline is continuously refined to improve relevance, accuracy, and system performance as data grows.
Beyond development, Nextwebi supports scalable deployment of RAG systems across cloud and hybrid infrastructures. We implement monitoring frameworks to track retrieval quality, response relevance, and model behavior, enabling ongoing refinement without retraining base models. This allows organizations to adapt quickly to evolving data while maintaining reliable, data-grounded GenAI applications.

Years in Business
Projects Delivered
Client Relationships
Countries Served
Our commitment to innovation, quality, and customer success has been recognized through prestigious industry awards and certifications. These achievements reflect the trust our clients place in us and our dedication to delivering exceptional digital solutions.





The technologies and tools that power our service delivery.
 HTML5
HTML5 CSS3
CSS3 JavaScript
JavaScript React
React Vue
Vue Ember
Ember Next.js
Next.js Angular
Angular Metor
Metor Python
Python .NET
.NET JAVA
JAVA Node
Node php
php Go
Go SharePoint
SharePoint Salesforce
Salesforce Dynamics 365
Dynamics 365 SAP
SAP AWS
AWS Azure
Azure Google
Google Oracle
Oracle PostgreSQL
PostgreSQL MySQL
MySQL MS SQL
MS SQL MongoDB
MongoDBNextwebi stands out as a Retrieval Augmented Generation company by designing RAG systems that are tightly aligned with enterprise data structures and real-world usage patterns. Our approach emphasizes retrieval precision, domain-aware embeddings, and optimized query pipelines, enabling AI applications to generate responses that remain grounded in relevant, authoritative data sources.
What differentiates Nextwebi is our focus on production stability and controlled AI behavior. We build RAG architectures with built-in governance, access control, and performance monitoring, allowing organizations to scale GenAI applications securely while maintaining accuracy, relevance, and long-term system reliability.
At Nextwebi, our RAG development process follows a structured, data-centric lifecycle—designed to power GenAI applications with accurate, contextual, and trustworthy responses.
We identify GenAI use cases, define response accuracy requirements, and assess enterprise knowledge sources such as documents, databases, APIs, and internal systems.
We clean, chunk, enrich, and structure data while applying metadata, access controls, and governance to prepare high-quality knowledge for retrieval.
We design embedding strategies, select vector databases, and configure retrieval logic to ensure fast, relevant, and context-aware information retrieval.
We integrate large language models with retrieval pipelines, apply prompt templates, grounding logic, and guardrails to generate accurate, explainable responses.
We validate response accuracy, latency, and security, deploy RAG pipelines into production, and continuously optimize retrieval quality and model performance.
Let's talk about how we can craft a user experience that not only
looks great but drives real growth for your product.!
Here's what our clients' have to say about us
Read more to find out about the frequently asked questions
RAG development services encompasses the building of AI systems that combine semantic retrieval with generative models, allowing responses to be generated using relevant enterprise or domain-specific data instead of relying only on pretrained knowledge.
Years in Business
Projects Delivered
Client Relationships
Countries Served
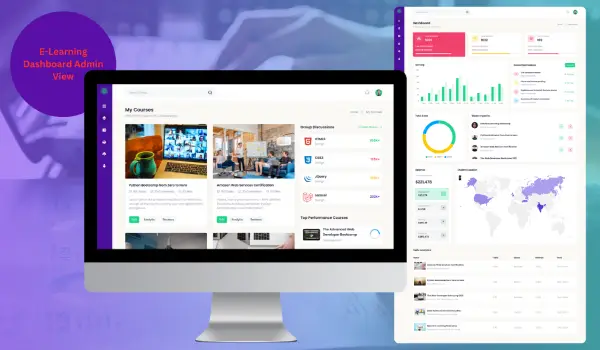
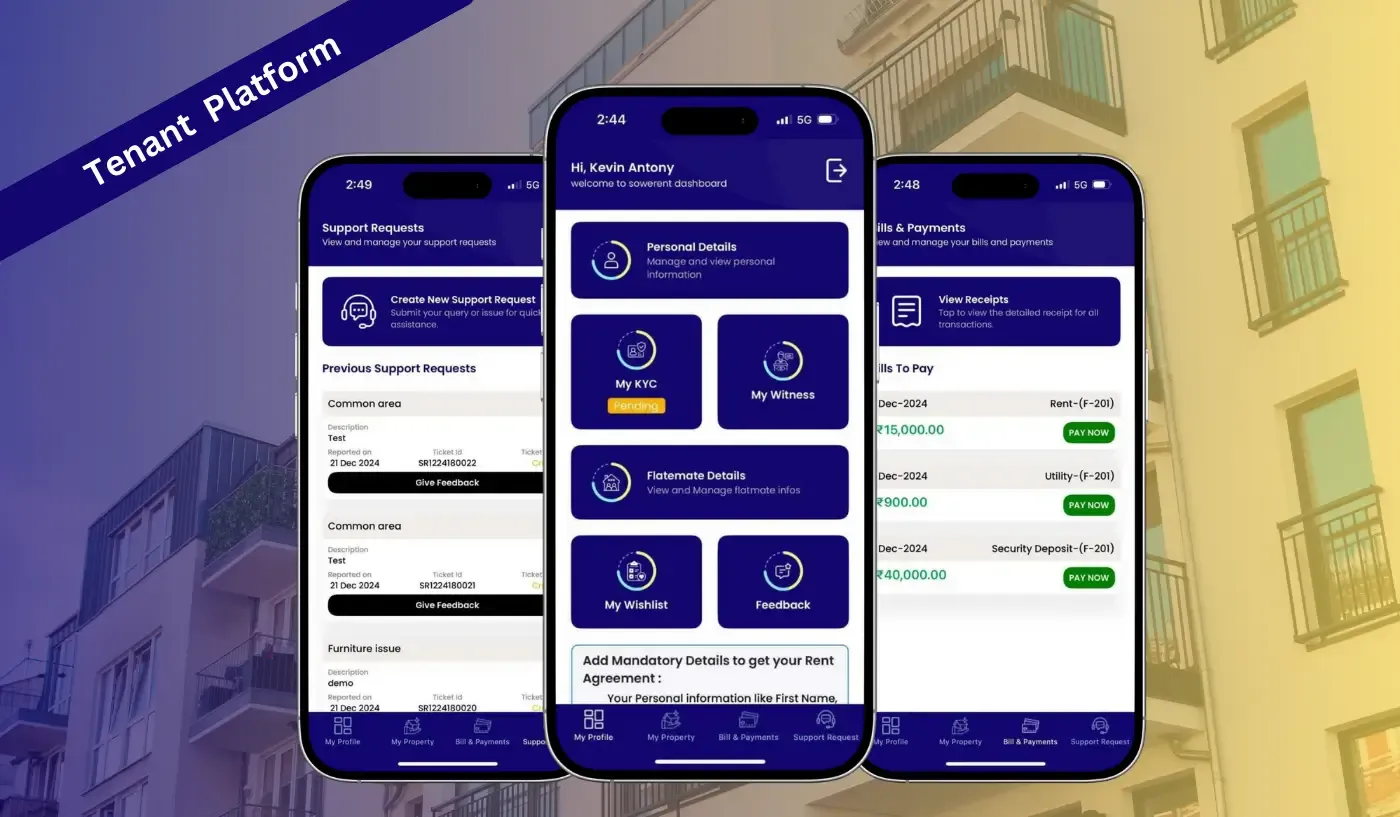
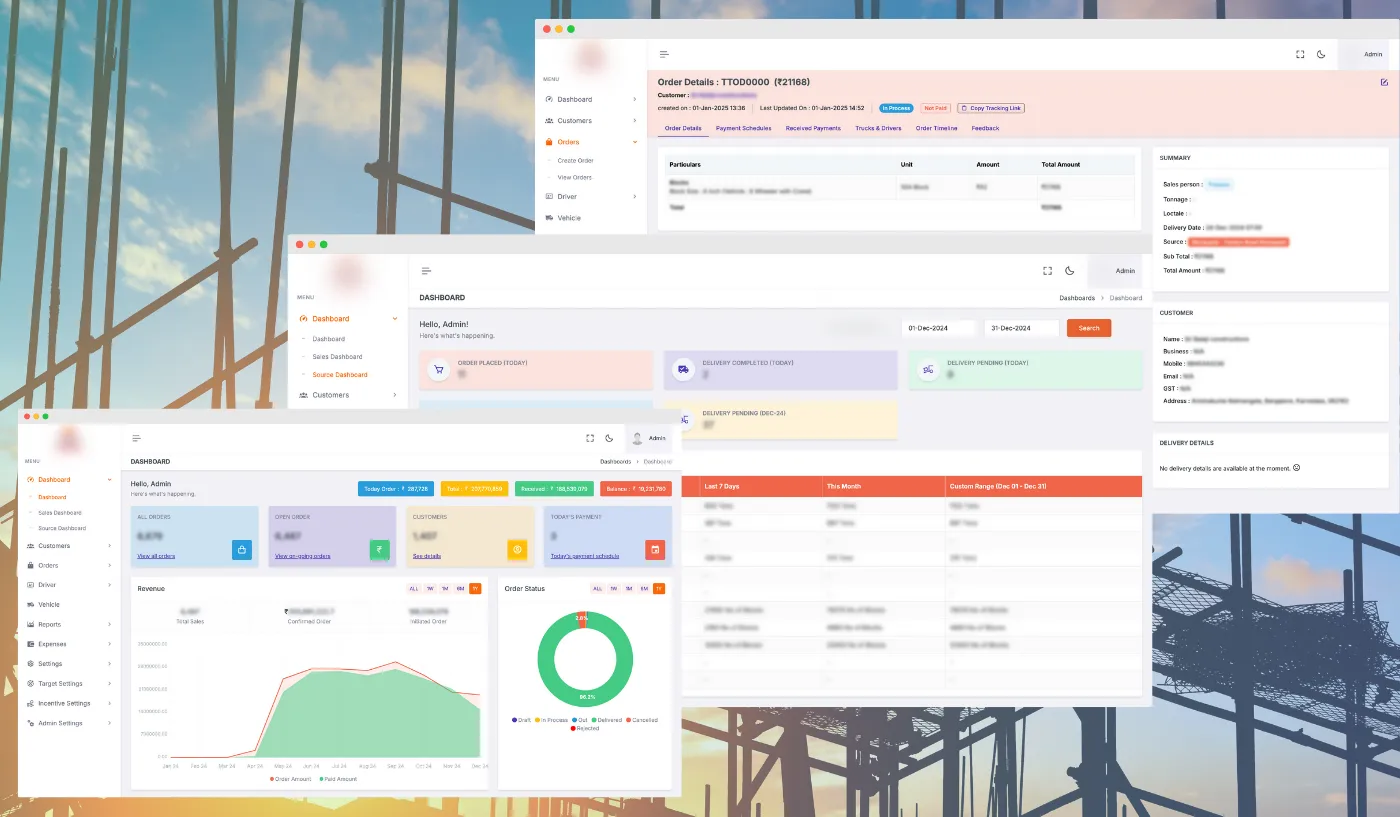
Assisting brands to make a digital impact.
Assisting brands to make a digital impact.
Assisting brands to make a digital impact.
Assisting brands to make a digital impact.
Assisting brands to make a digital impact.